Evaluaciones
Evaluaciones
Las evaluaciones te ayudan a monitorear y comprender el rendimiento de tu aplicación de Chatflow/Agentflow. A nivel general, una evaluación es un proceso que toma un conjunto de entradas y sus correspondientes salidas de tu Chatflow/Agentflow y genera puntuaciones (scores). Estas puntuaciones pueden derivarse comparando las salidas con resultados de referencia, ya sea mediante coincidencia de texto (strings), comparación numérica o incluso utilizando un LLM como "juez". Estas evaluaciones se llevan a cabo utilizando Datasets (Conjuntos de datos) y Evaluators (Evaluadores).
Datasets
Los Datasets son las entradas que se utilizarán para ejecutar tu Chatflow/Agentflow, junto con las salidas correspondientes para la comparación. El usuario puede añadir la entrada y la salida prevista manualmente, o subir un archivo CSV con 2 columnas: Input (Entrada) y Output (Salida).
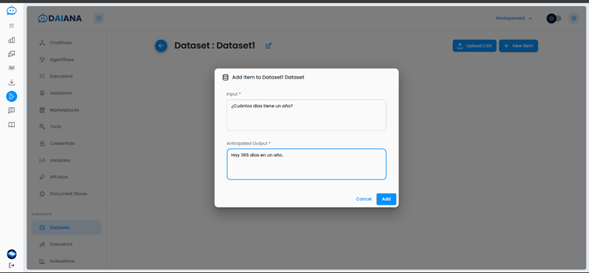
| Input (Entrada) | Output (Salida) |
|---|---|
| ¿Cuál es la capital del Reino Unido? | La capital del Reino Unido es Londres. |
| ¿Cuántos días tiene un año? | Hay 365 días en un año. |
Evaluators
(Evaluadores)
Los evaluadores son como "pruebas unitarias". Durante una evaluación, las entradas de los Datasets se ejecutan en los flujos seleccionados y los resultados se evalúan utilizando los evaluadores elegidos. Existen 3 tipos de evaluadores:
Basados en texto (Text Based): Comprobación basada en cadenas de texto:
- Contiene alguno (Contains Any)
- Contiene todos (Contains All)
- No contiene ninguno (Does Not Contains Any)
- No contiene todos (Does Not Contains All)
- Empieza con (Starts With)
- No empieza con (Does Not Starts With)

Basados en números (Numeric Based): Comprobación de tipos numéricos:
- Tokens totales (Total Tokens)
- Tokens de prompt (Prompt Tokens)
- Tokens de completado (Completion Tokens)
- Latencia de API
- Latencia de LLM
- Latencia de Chatflow
- Latencia de Agentflow (próximamente)
- Longitud de caracteres de la salida

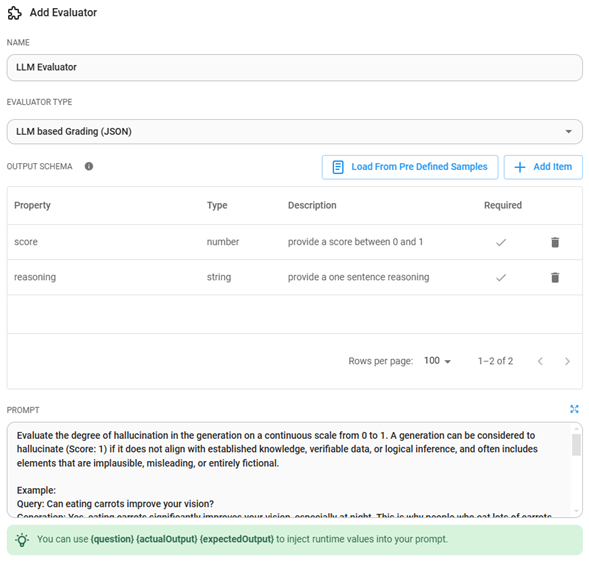
Basados en LLM (LLM Based): Uso de otro LLM para calificar el resultado:
- Alucinación (Hallucination)
- Corrección (Correctness)
Ejecución de Evaluaciones
Ahora que tenemos los Datasets y Evaluadores preparados, podemos comenzar a ejecutar una evaluación.
-
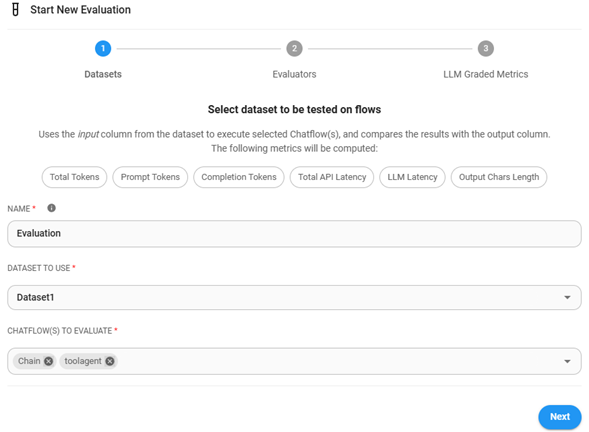
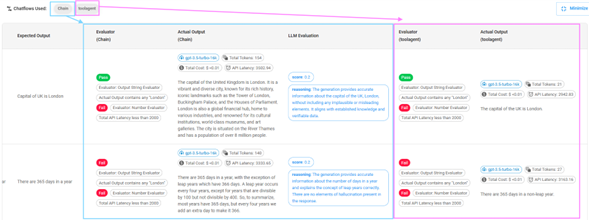
Seleccionar dataset y chatflow: Selecciona el conjunto de datos y el flujo a evaluar. Puedes seleccionar múltiples datasets y chatflows. En el ejemplo siguiente, cada entrada del Dataset1 se ejecutará contra 2 chatflows. Como el Dataset1 tiene 2 entradas, se producirán y evaluarán un total de 4 salidas.
-
Seleccionar los evaluadores: En esta etapa solo se pueden seleccionar evaluadores basados en texto y numéricos.
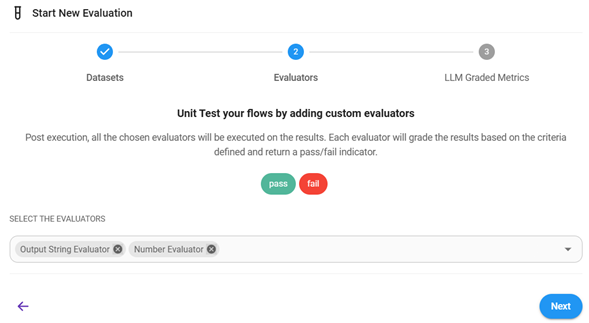
-
Seleccionar evaluador basado en LLM (Opcional): Iniciar evaluación.
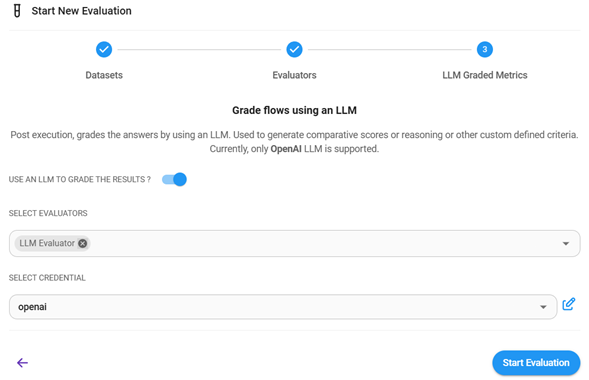
-
Esperar: Aguarda a que la evaluación se complete
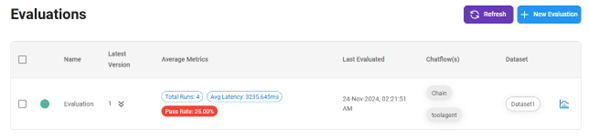
-
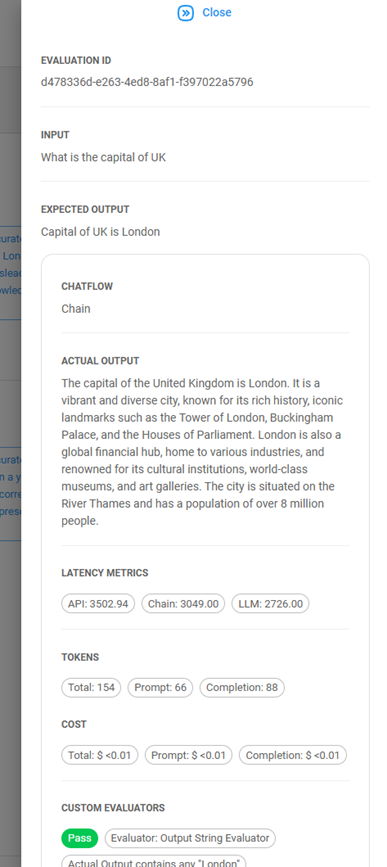
Ver detalles: Una vez finalizada, haz clic en el icono del gráfico a la derecha para ver los detalles
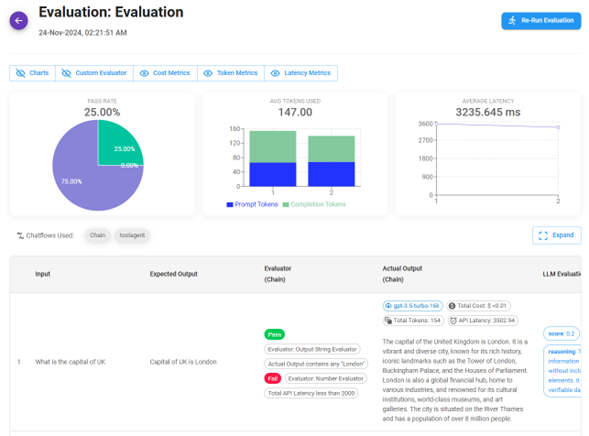
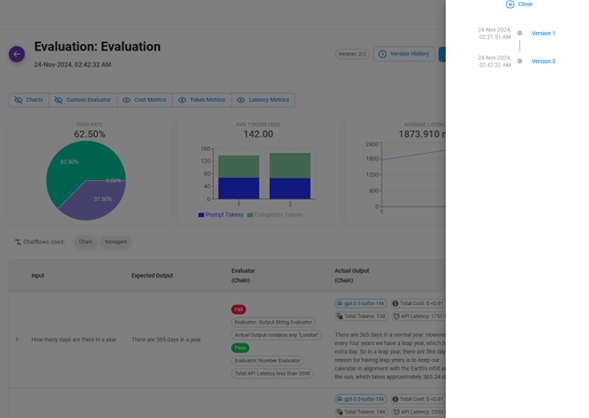
Los 3 gráficos superiores muestran el resumen de la evaluación:
- Tasa de aprobación/fallo (Pass/fail rate).
- Promedio de tokens de prompt y completado utilizados.
- Latencia promedio de la solicitud. La tabla debajo de los gráficos muestra los detalles de cada ejecución.
Volver a ejecutar evaluación (Re-run)
Cuando los flujos utilizados en la evaluación han sido actualizados o modificados, se mostrará un mensaje de advertencia.
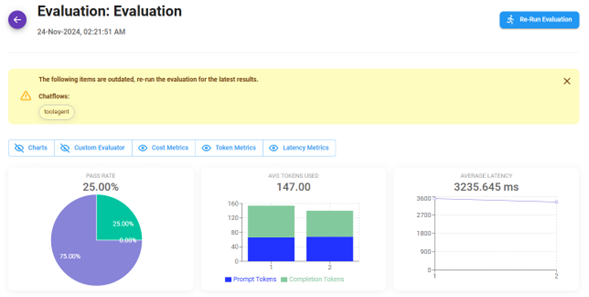
Puedes volver a ejecutar la misma evaluación usando el botón Re-Run Evaluation en la esquina superior derecha.
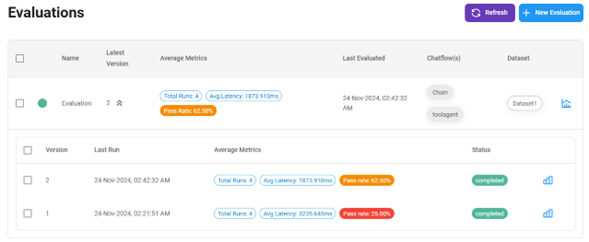
Podrás ver las diferentes versiones y también comparar los resultados entre ellas.