Deep Research
Deep Research
El Agente de Investigación Profunda (Deep Research Agent) es un sistema multi-agente sofisticado que puede realizar investigaciones exhaustivas sobre cualquier tema. Para ello, desglosa consultas complejas en tareas manejables, despliega agentes de investigación especializados y sintetiza los hallazgos en informes detallados.
Este enfoque está inspirado en el blog de Anthropic: Cómo construimos nuestro sistema de investigación multi-agente.
Resumen General
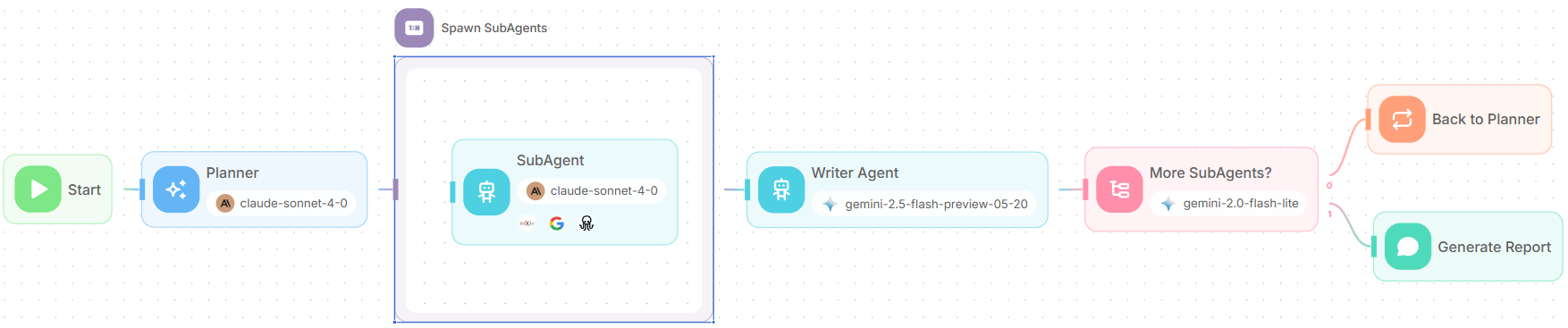
El flujo de trabajo del Agente de Investigación Profunda consta de varios componentes clave que trabajan en conjunto:
- Agente Planificador (Planner Agent): Analiza la consulta de investigación y genera una lista de tareas de investigación especializadas.
- Iteración: Crea múltiples agentes de investigación para trabajar en diferentes aspectos de la consulta.
- SubAgentes de Investigación (Research SubAgents): Agentes individuales que realizan investigaciones focalizadas utilizando la búsqueda web y otras herramientas.
- Agente Escritor (Writer Agent): Sintetiza todos los hallazgos en un informe coherente y completo.
- Agente de Condición (Condition Agent): Determina si se necesita investigación adicional o si los hallazgos son suficientes.
- Bucle (Loop): Regresa al Agente Planificador para mejorar la calidad de la investigación.
Paso 1: Crear el Nodo de Inicio (Start)

- Comience agregando un nodo Start a su lienzo.
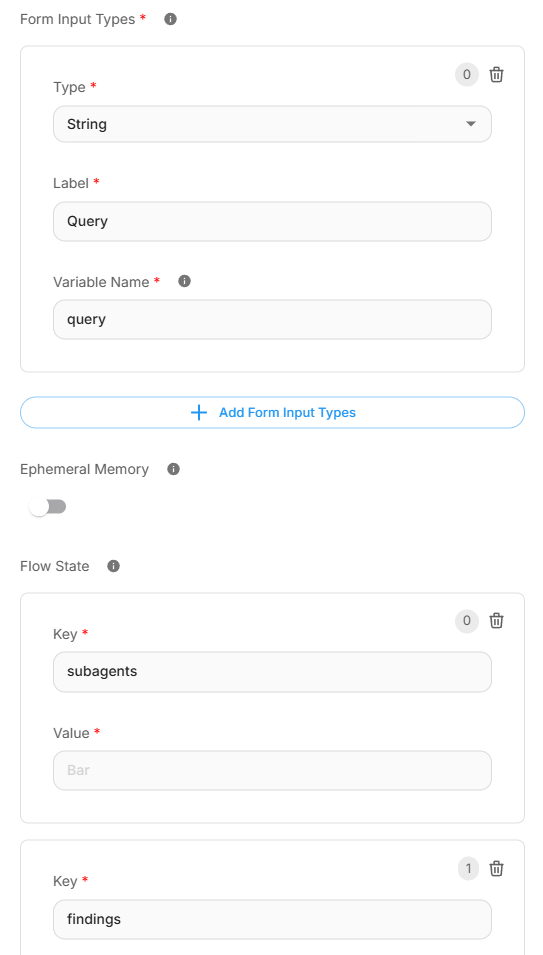
- Configure el nodo Start con Form Input (Entrada de Formulario) para recopilar la consulta de investigación de los usuarios.
- Configure el formulario de la siguiente manera:
- Título del Formulario: "Investigación"
- Descripción del Formulario: "Un agente de investigación que recibe una consulta y devuelve un informe detallado"
- Tipos de Entrada de Formulario: Agregue una entrada de cadena (string) con la etiqueta "Consulta" y el nombre de variable "query".
- Inicialice el Estado del Flujo (Flow State) con dos variables clave:
subagents: Para almacenar la lista de tareas de investigación que llevarán a cabo los subagentes.findings: Para acumular los resultados de la investigación.
Paso 2: Agregar el Agente Planificador (Planner Agent)

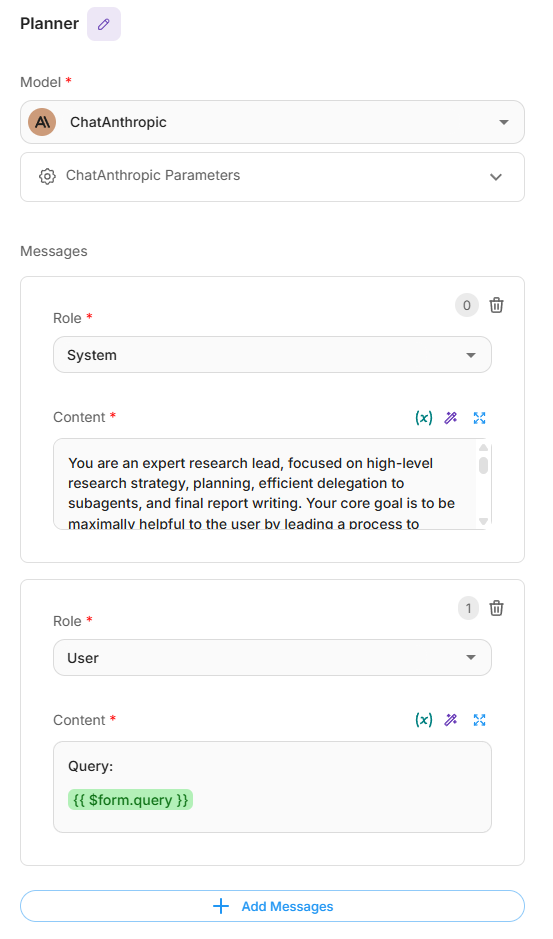
- Conecte un nodo LLM al nodo Start.
- Configure el mensaje del sistema para que actúe como un líder de investigación experto con las siguientes responsabilidades clave:
- Analizar y desglosar las consultas de los usuarios.
- Crear planes de investigación detallados.
- Generar tareas específicas para los subagentes.
- Ejemplo de prompt - research_lead_agent.md
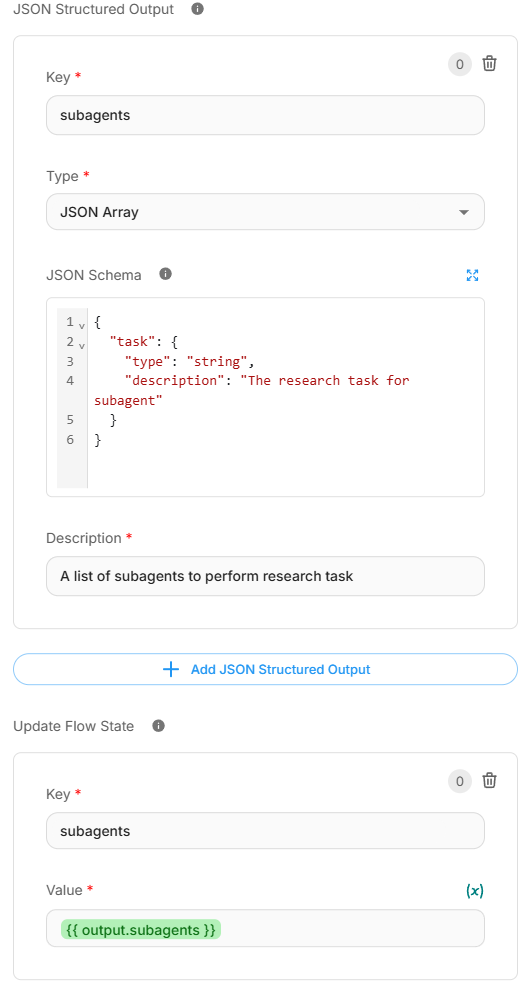
- Configure la Salida Estructurada JSON (JSON Structured Output) para devolver una lista de tareas para los subagentes:
{
"task": {
"type": "string",
"description": "The research task for subagent"
}
}
- Actualice el estado del flujo almacenando la lista de subagentes generada.
Paso 3: Crear el Bloque de Iteración de SubAgentes
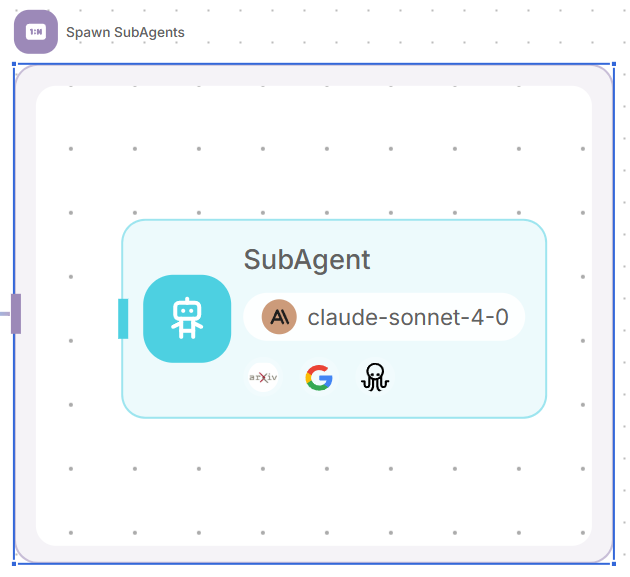
- Agregue un nodo Iteration (Iteración).
- Conéctelo a la salida del Planificador (Planner).
- Configure la entrada de iteración al estado del flujo:
{{ $flow.state.subagents }}. Por cada elemento en la matriz, se generará un subagente para llevar a cabo la tarea de investigación. Ejemplo:
Paso 4: Construir el SubAgente de Investigación
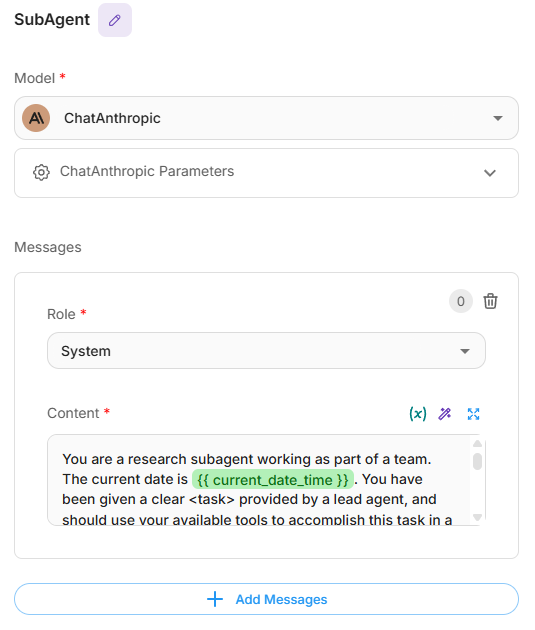
- Dentro del bloque de iteración, agregue un nodo Agent.
- Configure el mensaje del sistema para que actúe como un subagente de investigación enfocado con:
- Capacidades claras de comprensión de tareas.
- Planificación eficiente de la investigación (2-5 llamadas a herramientas por tarea).
- Evaluación de la calidad de las fuentes.
- Uso de herramientas en paralelo para mayor eficiencia.
- Ejemplo de prompt - research_subagent.md
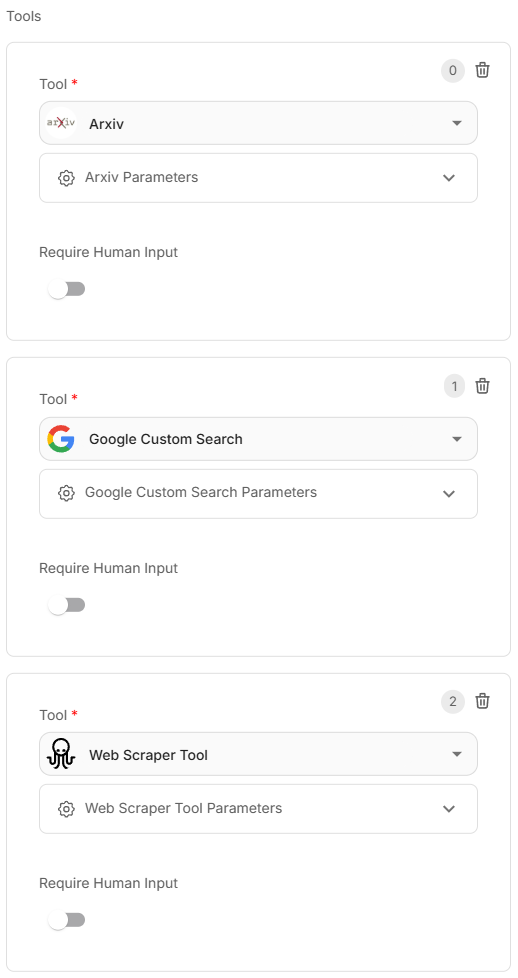
- Agregue las siguientes herramientas de investigación (puede usar sus herramientas preferidas):
- Google Search: Para enlaces de búsqueda web.
- Web Scraper: Para la extracción de contenido web. Esto extraerá el contenido de los enlaces de Google Search.
- ArXiv Search: Para buscar y cargar contenido de artículos académicos.
- Establezca el mensaje del usuario para pasar la tarea de la iteración actual:
{{ $iteration.task }}
Paso 5: Agregar el Agente Escritor (Writer Agent)
- Conecte un nodo LLM después de que se complete la iteración.
- Se necesita un LLM de contexto grande como Gemini (con un tamaño de contexto de 1 a 2 millones) para sintetizar todos los hallazgos y generar el informe.
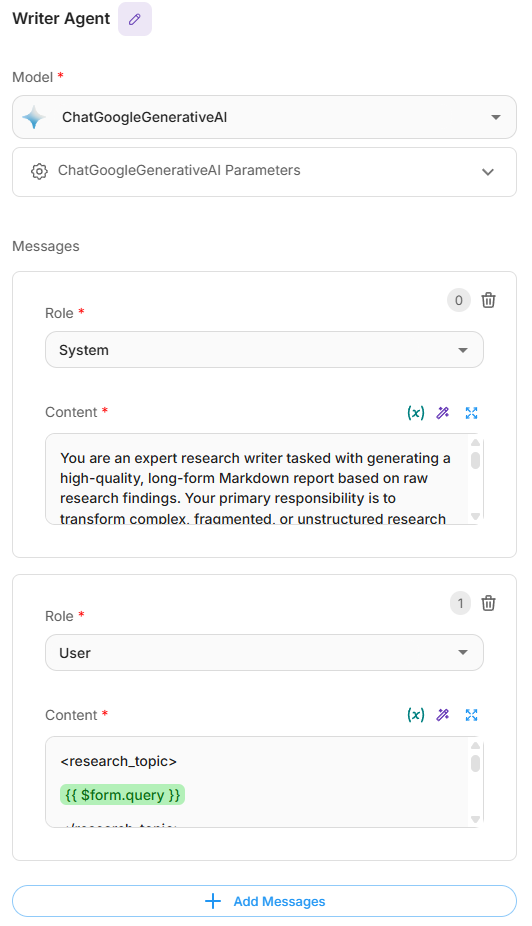
- Configure el mensaje del sistema para que actúe como un escritor de investigación experto que:
- Preserve el contexto completo de los hallazgos de la investigación.
- Mantenga la integridad de las citas.
- Agregue estructura y claridad.
- Genere informes profesionales en formato Markdown.
- Configure el mensaje del usuario para incluir:
- Tema de investigación:
{{ $form.query }} - Hallazgos existentes:
{{ $flow.state.findings }} - Nuevos hallazgos:
{{ iterationAgentflow_0 }}
- Tema de investigación:
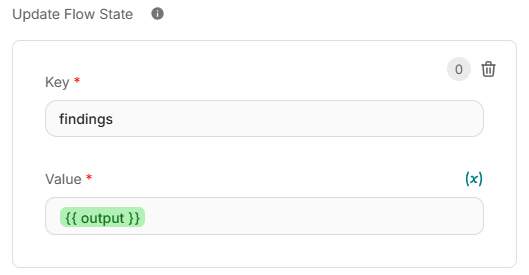
- Actualice
{{ $flow.state.findings }}con la salida del Agente Escritor (Writer Agent).
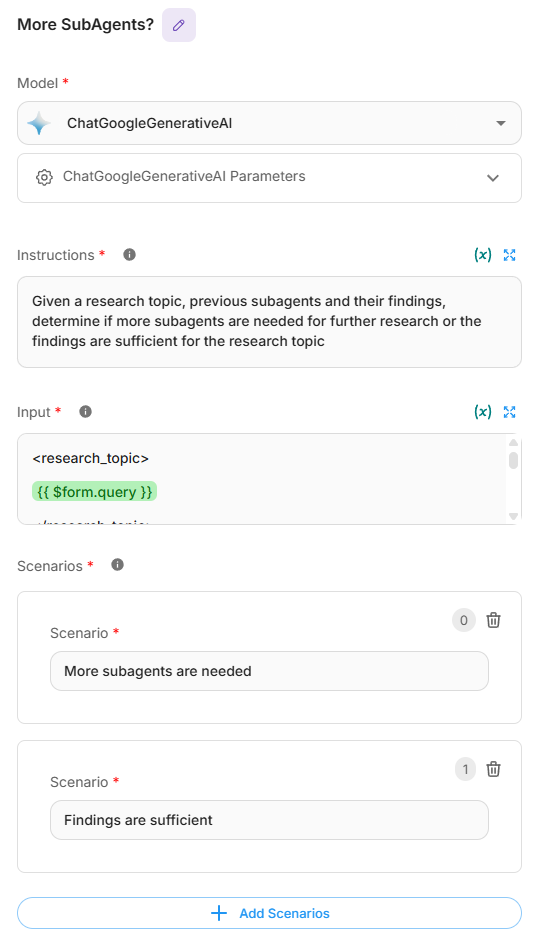
Paso 6: Implementar la Verificación de Condición
- Agregue un Condition Agent (Agente de Condición).
- Configure la lógica de condición para determinar si se necesita investigación adicional.
- Configure dos escenarios:
- "Se necesitan más subagentes"
- "Los hallazgos son suficientes"
- Proporcione contexto de entrada que incluya:
- Tema de investigación
- Lista actual de subagentes
- Hallazgos acumulados
Paso 7: Crear el Mecanismo de Bucle (Loop)
- Para la ruta "Se necesitan más subagentes", agregue un nodo Loop.
- Configúrelo para que vuelva al nodo del Planificador (Planner).
- Establezca un conteo máximo de bucles de 5 para evitar bucles infinitos.
- El Agente Planificador revisará el informe actual y generará tareas de investigación adicionales.

Paso 8: Agregar la Salida Final
- Para la ruta "Los hallazgos son suficientes", agregue un Direct Reply (Respuesta Directa).
- Configúrelo para mostrar el informe final:
{{ $flow.state.findings }}


Probar el Flujo
- Comience con un tema simple como "Sistemas multi-agente autónomos en entornos del mundo real".
- Observe cómo el Planificador desglosa la investigación en tareas focalizadas.
- Monitoree a los SubAgentes mientras realizan investigaciones en paralelo.
- Revise la síntesis de hallazgos del Agente Escritor.
- Note si el Agente de Condición solicita investigación adicional.
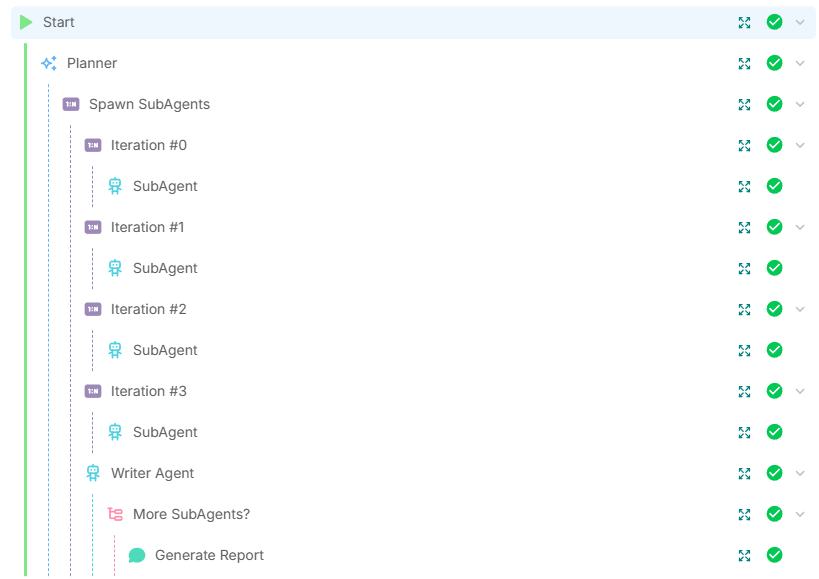
Tutorial (Walkthrough)
- 🧠 Agente Planificador - analiza la consulta de investigación y genera una lista de tareas de investigación especializadas.
- 🖧 Subagentes - crean múltiples subagentes de investigación, realizan investigaciones focalizadas usando herramientas de búsqueda web, raspado web y ArXiv.
- ✍️ Agente Escritor - sintetiza todos los hallazgos en un informe coherente y completo con citas.
- ⇄ Agente de Condición - determina si se necesita investigación adicional o si los hallazgos son suficientes.
- 🔄 Bucle hacia el Agente Planificador para generar más subagentes.
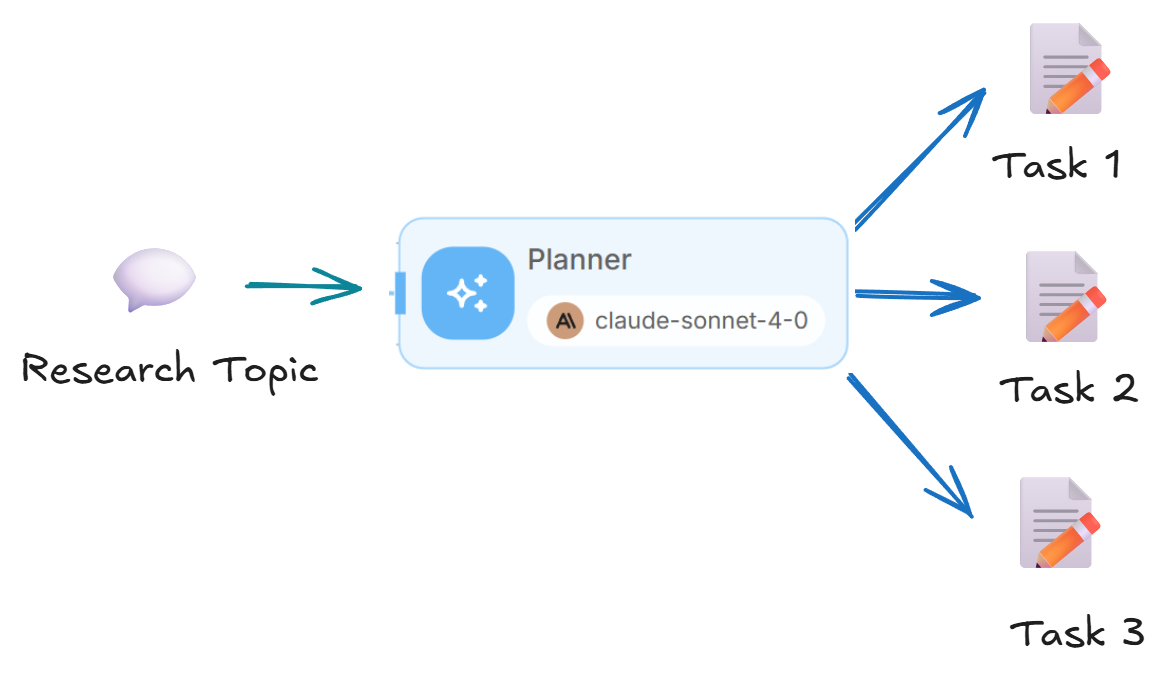
🧠 Agente Planificador (Planner Agent)
Actúa como un líder de investigación experto para:
- Analizar y desglosar las consultas de los usuarios.
- Crear planes de investigación detallados.
- Generar tareas específicas para los subagentes.
Salida de una matriz de tareas de investigación.
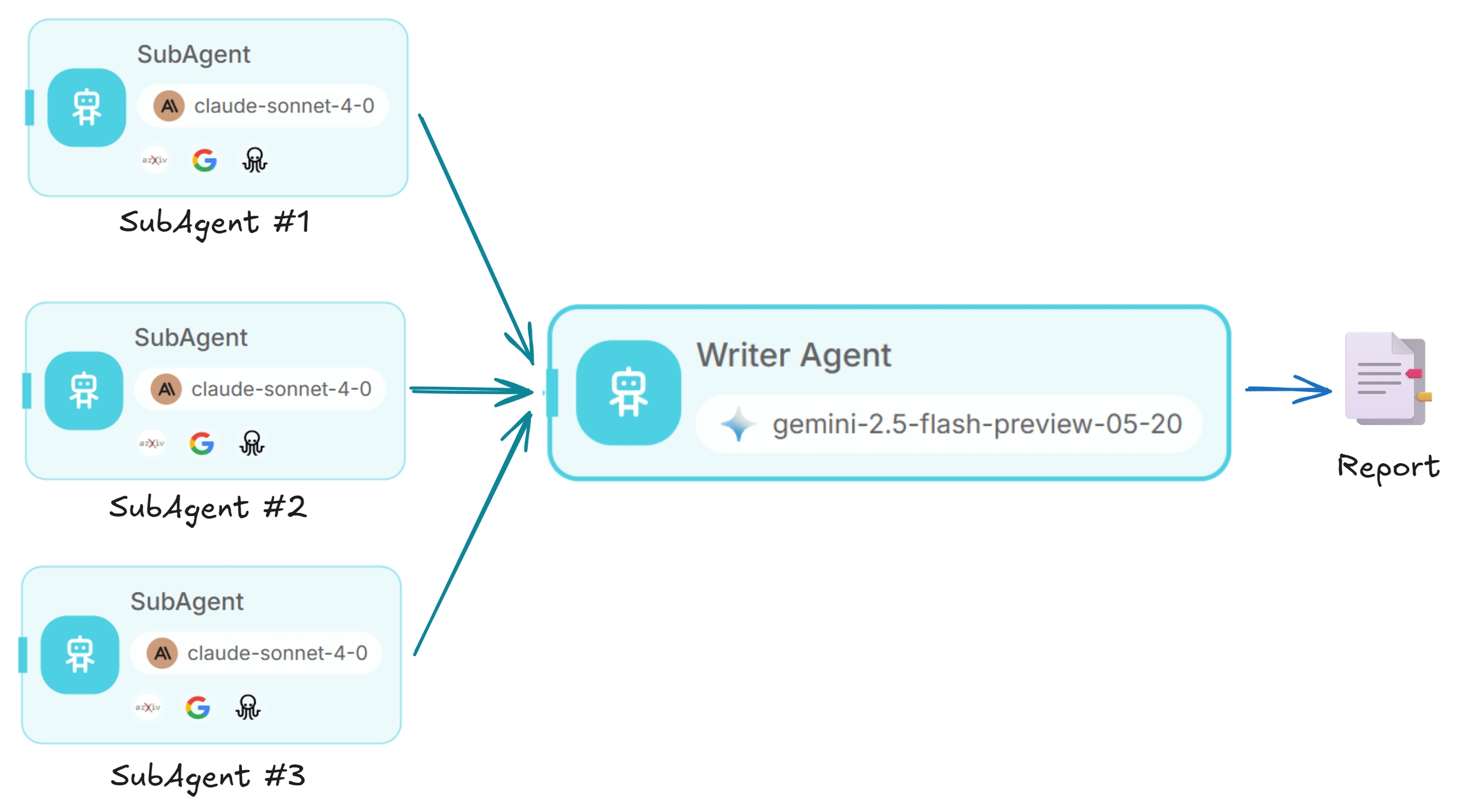
🖧 Subagentes
Por cada tarea en la lista, se generará un nuevo subagente para realizar investigaciones focalizadas.
Cada subagente tiene:
- Capacidades claras de comprensión de tareas.
- Planificación eficiente de la investigación (2-5 llamadas a herramientas por tarea).
- Evaluación de la calidad de las fuentes.
- Uso de herramientas en paralelo para mayor eficiencia.
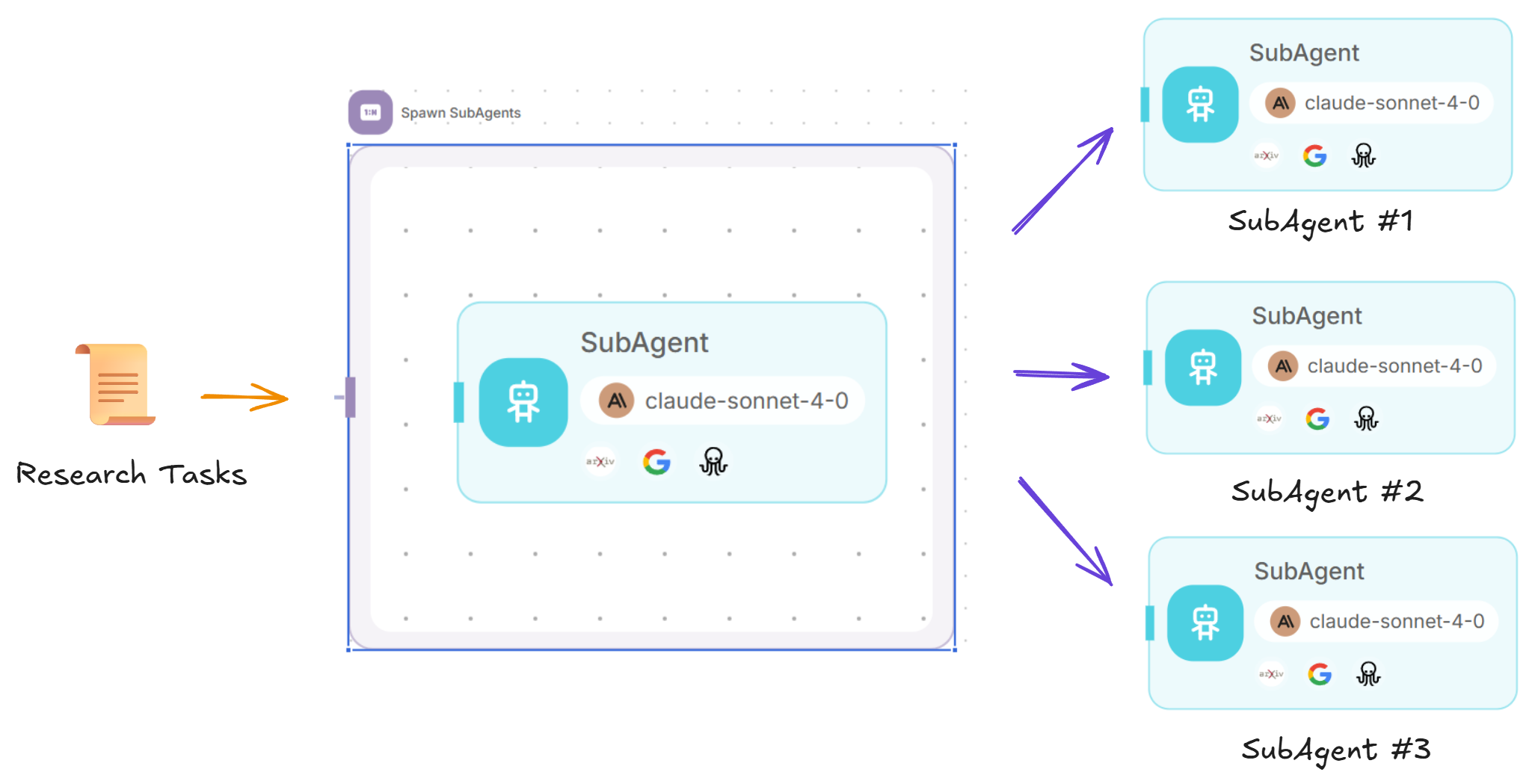
El subagente tiene acceso a herramientas de búsqueda web, raspado web y ArXiv.
- 🌐 Google Search - para enlaces de búsqueda web.
- 🗂️ Web Scraper - para la extracción de contenido web. Esto extraerá el contenido de los enlaces de Google Search.
- 📑 ArXiv - buscar, descargar y leer el contenido de artículos de ArXiv.
✍️ Agente Escritor (Writer Agent)
Actúa como un escritor de investigación que convierte los hallazgos en bruto en un informe estructurado y claro en Markdown. Preserva todo el contexto y las citas.
Consideramos que Gemini es el mejor para esto, gracias a su gran ventana de contexto que le permite sintetizar todos los hallazgos de manera efectiva.
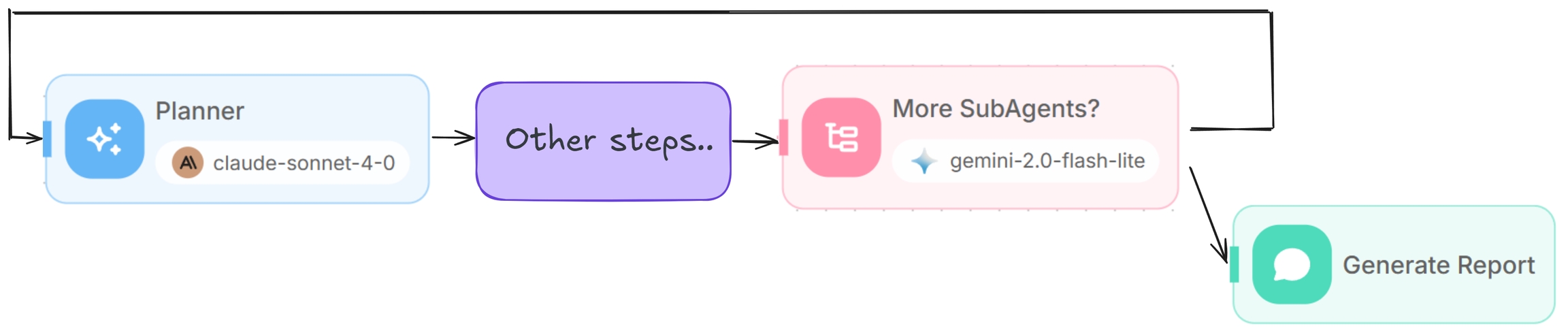
⇄ Agente de Condición (Condition Agent)
Con el informe generado, dejamos que el LLM determine si se necesita investigación adicional o si los hallazgos son suficientes.
Si se necesita más, el Agente Planificador revisa todos los mensajes, identifica áreas de mejora, genera tareas de investigación de seguimiento y el bucle continúa.
Si los hallazgos son suficientes, simplemente devolvemos el informe final del Agente Escritor como la salida.
Configuración Avanzada
Personalización de la Profundidad de la Investigación
Puede ajustar la profundidad de la investigación modificando el prompt del sistema del Planificador para:
- Aumentar el número de SubAgentes para temas complejos (hasta 10-20).
- Ajustar el presupuesto de llamadas a herramientas por SubAgente.
- Modificar el conteo de bucles para una investigación más iterativa.
Sin embargo, esto también conlleva un costo adicional por un mayor consumo de tokens.
Adición de Herramientas Especializadas
Mejore las capacidades de investigación agregando herramientas específicas de dominio:
- Herramientas personales como Gmail, Slack, Google Calendar, Teams, etc.
- Otros raspadores web, herramientas de búsqueda web como Firecrawl, Exa, Apify, etc.
Adición de Contexto RAG
Puede agregar más contexto al LLM con RAG. Esto permite que el LLM obtenga información de fuentes de conocimiento existentes relevantes cuando sea necesario.